- Published on
Simple Lambda Cache with Ephemeral Storage
- Authors
- Name
- Bartosz Golebiowski
- @BartoszEbiowski


Introduction
In this article, we explore how to use AWS Lambda to create a simple cache with ephemeral storage for API calls. Its ephemeral storage feature provides temporary data storage to enhance application performance. We'll discuss the benefits of this approach, how to set it up, and what it can do for your cloud applications.
Ephermal Storage
This ephemeral storage is temporary and exists only during the lambda execution context. The more frequently a Lambda function is invoked, the more likely AWS will keep the execution context alive. The developer can use this feature to store data between invocations of the same function. This behavior can be helpful to for caching data, reducing the need to fetch it from external sources repeatedly, but the ephemeral storage has many other use cases.
In case of a cold start, the data stored in the ephemeral storage will be lost. The data stored in the ephemeral storage is not shared between different invocations of the different lambda execution contexts.
In case of a concurrent execution, the data stored in the ephemeral storage is not shared between different concurrent executions of the same function. Each concurrent execution has its ephemeral storage.
Use Case
Let's consider a scenario where an API fetches data from an external source. This data is relatively static and doesn't change frequently. Instead of fetching the data from the external source every time the API is called, we can cache the data in the ephemeral storage of the Lambda function. This approach can reduce the API calls' latency and improve the application's overall performance.
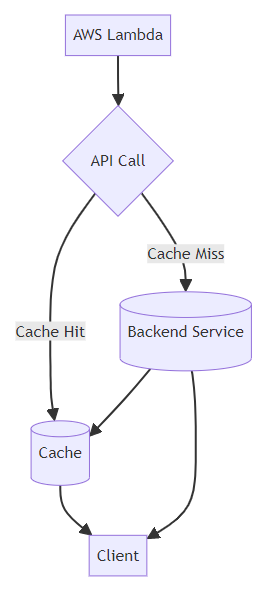
Lambda Function
To implement this cache, we create an AWS Lambda function that fetches data from the external source and caches it in ephemeral storage. When the Lambda function is invoked, it first checks if the data is present in the cache. If the data is found, it returns the cached data. If the data is not found, it fetches the data from the external source, caches it in the ephemeral storage, and returns it to the client.
import { CacheResponse } from './cache.mjs'
import { JSONPlaceholderClient } from './client.mjs'
const ONE_MINUTE = 1000 * 60
const cache = new CacheResponse('todos', ONE_MINUTE)
const client = new JSONPlaceholderClient()
export const lambdaHandler = async (event) => {
const id = event.pathParameters.id
const todos = cache.read(id, Date.now())
if (todos) {
return {
statusCode: 200,
headers: {
'X-Cache-Hit': 'true',
'X-Cache-Expiry': todos.expiry,
},
body: JSON.stringify({
todos,
}),
}
}
try {
const todos = await client.get(id)
const cached = cache.write(id, todos)
return {
statusCode: 200,
headers: {
'X-Cache-Hit': 'false',
'X-Cache-Expiry': cached.expiry,
},
body: JSON.stringify({
todos,
}),
}
} catch (err) {
console.log(err)
return {
statusCode: 500,
body: JSON.stringify({
message: 'Internal Server Error',
}),
}
}
}
In the code snippet above, we define an AWS Lambda function that fetches data from an external source using the JSONPlaceholderClient class. We create a cache object using the CacheResponse class and set an expiry time of one minute for the cached data. If the data is present in the cache, it returns the cached data with a 200 status code and the appropriate headers. If the data is not in the cache, it fetches the data from the external source, caches it, and returns it to the client.
Cache Implementation
The cache implementation is a simple key-value store that stores the data in the ephemeral storage of the Lambda function. The cache object has methods to read and write data to the cache. The cache data is stored as an object with the data payload. When reading from the cache, the method checks if the data is still valid based on the expiry timestamp. If the data is expired, it returns null, indicating a cache miss. If the data is still valid, it returns the cached data.
export class CacheResponse {
constructor(cacheKey, ttl) {
this.cacheKey = `/tmp/${cacheKey}`
this.cacheMetaKey = `/tmp/meta/${cacheKey}`
this.ttl = ttl
}
read(id, now) {
try {
const metaKey = `${this.cacheMetaKey}-${id}`
const metaRaw = fs.readFileSync(metaKey, 'utf8')
const meta = JSON.parse(metaRaw)
if (now - meta.timestamp > this.ttl) {
return null
}
const key = `${this.cacheKey}-${id}`
const todosRaw = fs.readFileSync(key, 'utf8')
if (todosRaw) {
const todos = JSON.parse(todosRaw)
const expiry = new Date(meta.timestamp + this.ttl).toISOString()
return {
data: todos,
expiry: expiry,
}
}
} catch (err) {
console.log('Error reading from cache', err)
}
return null
}
write(id, data) {
const meta = {
timestamp: Date.now(),
}
const key = `${this.cacheKey}-${id}`
const metaKey = `${this.cacheMetaKey}-${id}`
fs.writeFileSync(metaKey, JSON.stringify(meta))
fs.writeFileSync(key, JSON.stringify(data))
return {
expiry: new Date(meta.timestamp + this.ttl).toISOString(),
}
}
}
This implementation can be replaced with an in-memory cache like Map or WeakMap for better performance, but in case of working with bigger data, it would be beneficial to use ephemeral storage. This implementation stores JSON files from the external API, but it can be easily modified to store any other data, like files, images, etc.
Conclusion
In this article, we explored creating a simple cache with ephemeral storage using AWS Lambda. This approach is a naive approach for caching data in the Lambda function, but it can be helpful in scenarios where the data is relatively static and doesn't change frequently. By caching the data we can reduce the latency of API calls and improve the application's overall performance, and mitigate the timeout issues.
Procs:
- Simple
- Easy to implement
- No additional cost for storage
- Can store JSON, files, images, etc.
- Ephemeral storage can store up to 10GB
- Mitigates the need to fetch data from external sources repeatedly
Cons:
- The lambda can serve stale data
- Data is lost in case of cold start
- Data is not shared between concurrent executions
- Data is lost after the execution context is destroyed